Siri و Cortana كانتا المثال الأكثر انتشاراً لواجهة المستخدم User Interface التي تعتمد على الصوت، حتى أصدرت Google و Amazon مؤخراً العديد من الأجهزة devices التي تدعم الواجهة الصوتية Voice Inerface، والتي وجدت طريقها لملايين المستخدمين عبر العالم منذ العام الماضي .
وتتضاعفت هذا العام لتصل لأكثر من 24.5 مليون جهاز، وفقاً للإحصائيات التي أجرتها شركة analysis from VoiceLabs ، مما يفتح مجالاً أكبر للمصممين لتصميم التجارب و الواجهات الصوتية Voice Interface Designer.
تصميم واجهة جديدة لا يعني تجاهل الواجهات التي تم تصميمها مسبقاً، وما حققته من نجاح في تجربة الاستخدام UX ، بل يجب أن نستند إلى الدراسات التي أجريت علىها مع مراعاة الاختلافات بينها وبين الواجهات الصوتية مثل التفاعلات التخاطبية Voice Ineraction، لنتمكن من عمل تصميم واضح الخطوات يفهمه المستخدم ويستطيع التكيف معه.
واجهة الصوت Voice Interface وكيفية فهمها؟
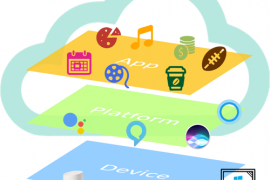
مثلما تعمل تطبيقات الجوال Mobile Apps على محورين أساسيين هما نظام التشغيل OS، والجهاز device، كذلك تعمل التفاعلات الصوتية، ولكنها تعمل على ثلاثة محاور أساسية:
1- تطبيق الصوت Voice App : مثل AmazonSkills و Action For Google.
2- منصة الذكاء الاصطناعي Artificial intelligence platform : مثل Amazon Alexa و Google Assistant و Apple Siri و Cortana Microsoft .
3- الجهاز Device : مثل الهواتف الذكية، أجهزة الكمبيوتر و Echo .
كل طبقة من هذه الطبقات تعتمد على ما هو أسفل منها، وتدعم ما هو أعلى منها ، وتقع الواجهة الصوتية على الطبقتين العلويتين وهما الـ App و platform وليس على الجهاز Device نفسه.
الأجهزة التي تعتمد على الصوت مثل Amazon Echo و Google Home تتبع خطوات متتالية مرتبة لتخرج بالواجهة الصوتية وهى :
- الاستماع : حيث تستمع جيداً منتظرة سماع كلمة Alexa أو OK بالنسبة لـ Google.
- اتخاذ إجراء فعلي reaction: فبمجرد تفعيلها يقوم الجهاز بإرسال تسجيل الصوت التابع للإجراء إلى الـ Platform.
- يسمع المستخدم الرسالة الترحيبية بمجرد البدأ باستخدام التطبيق.

على سبيل المثال تطبيق Alexa حينما يستمع للكلمة المفتاحية فإنه يقوم بإرسال تسجيل صوتي إلى المنصة التابعة له Play jeopardy Platform التي تستخدم مزيج من التعريف التلقائي للكلام automatic speech recognition و الفهم اللغوي natural language understanding ثم تحوله إلى الخطاب الصوتي (welcome to jeopardy 6) الذي تسمعه من خلال الجهاز وكل هذا يحدث خلال ثوانِِ معدودة.
بناء تجربة صوتية Building Voice Experience.
Mark Zuckerberg أقبل على مغامرة وتحدي شخصي في العام الماضي، حيث قام بتصميم تطبيق بسيط يعتمد على الذكاء الاصطناعي Artificial intelligence أو AI لإدارة منزله، والذي أطلق عليه إسم Jarvis مستخدماً في واجهته الصوتية صوت voice of Morgan Freeman .

الواجهة الصوتية وعلاقتها بالذكاء الاصطناعي في jarvis app.
ويقول Mark عن jarvis app أنه كان تحدياً فكرياً مثيراً للإهتمام، حيث أعطى تجربة رائعة ومباشرة عن كيفية بناء أدوات الذكاء الاصطناعي المتعلقة بالمجالات المستقبلية.
ففي غضون 5 إلى 10 سنوات سيكون لدينا من أدوات الذكاء الاصطناعى AI tools ما يفوق حواسنا البشرية، كالسمع والرؤية واللمس فضلاً عن اللغة وكيفية فهمها.
لذا علينا التفكير بهذه التجارب الجديدة على نطاق أوسع ومعرفة الكيفية التي يتم بها إتخاذ فكرة من مجال معين وتطبيقها على مجالات أخرى ، فما المانع من استخدام تطبيق مثل jarvis في قيادة السيارات، اكتشاف الكواكب، علاج الأمراض، فهم وسائل الإعلام وغيرها لبناء دولة قوية قائمة على الذكاء الاصطناعي الذي يُعد هو لغة المستقبل.

حتى إذا لم يتوافر لدينا الموارد أو القدرة لبناء تطبيق يعتمد على واجهة صوتية منذ البداية، يمكنك العمل على منصات الذكاء الاصطناعي AI Platforms التي تم بناؤها بالفعل ، والتى وفرتها Amazon و Google كقوالب مفتوحة المصدر بكل ما فيها من تعليمات برمجية Codes وتفصيلية خطوة بخطوة، لتسطيع بناء أنواع مختلفة من التطبيقات الصوتية Voice apps. مما يوفر على مصمم التطبيق App designer ويرفع عائد ربح الشركات صاحبة هذه المنصات .

وبناء على ما سبق ،فإن النقطه التي تدعوا للقلق والتي يجب التركيز عليها والاهتمام بها هي معرفة كيفية تصميم الواجهة الصوتية والذي سنعرفه في الجزء الثاني من هذه السلسلة.
الخلاصة.
تعتبر التصميمات التي تعتمد على الواجهات الصوتية هي المستقبل، وذلك لارتباطها الوثيق بتصميمات الذكاء الاصطناعي ، مما يفتح لها المجال لاستخدامها في شتى المجالات ، كما فعلت كلاً من Google و Amazon و Microsoftو Apple في تطبيقاتها الصوتية التي أُطلقت مؤخراً ومن بعدهم Mark بالتطبيق الذي أطلقه عام 2016 والمُسمى بـ jarvis app .
مُترجم بتصرف عن: Designing Voice Experiences